刚用,拿来存储物联网数据,一个坑一个坑踩。
一、分区方面
1.1 分区数量过多问题
分区策略:终端ID+年月日

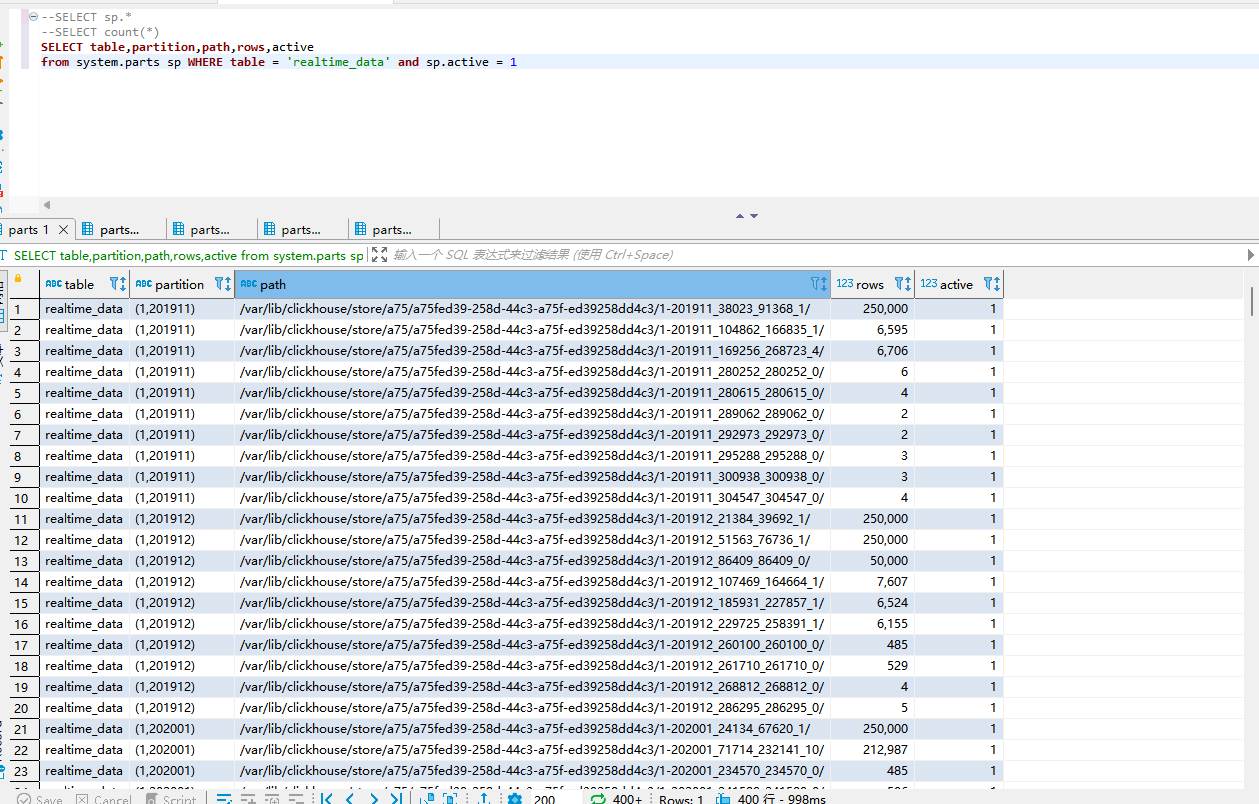
数据测试阶段,很快超过十万个分区后,数据无法插入:
Code: 252. DB::Exception: Too many parts (100025) in all partitions in total. This indicates wrong choice of partition key. The threshold can be modified with 'max_parts_in_total' setting in <merge_tree> element in config.xml or with per-table setting. (TOO_MANY_PARTS) (version 21.11.11.1 (official build))解决方法:分区策略:终端ID+年月
1.2 同分区多个分区目录问题
以为max_parts_in_total 已经解决了,但是很快又报错max_parts_in_total错误。
排查后发现,分区出现列表,导致分区数量激增,最多一个分区裂变为28个分区目录,占用了分区数量。具体看下图(1,201911)产生了多个分区目录。
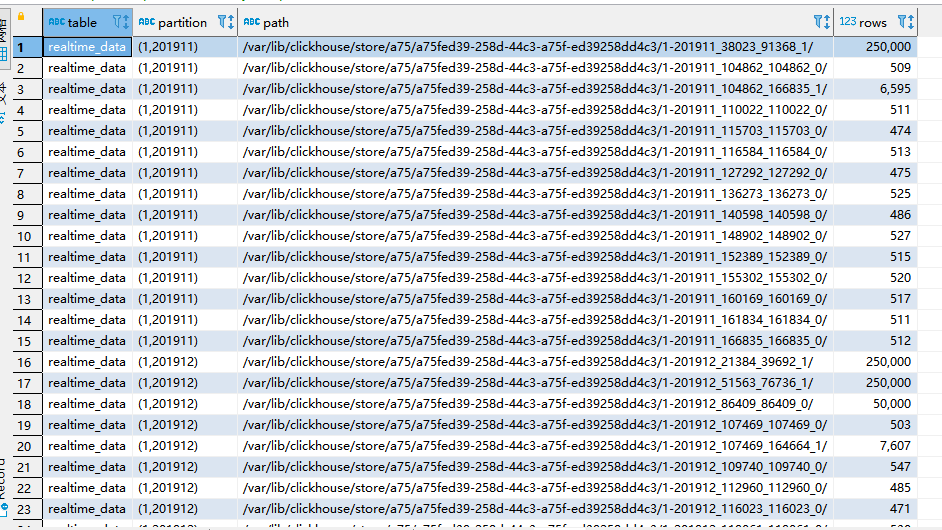
阅读《ClickHouse原理解析与应用实战》图书,作者:朱凯,后发现书中作者已经讲了分区目录产生与合并问题。
MergeTree数据写入过程中创建了分区目录,所以同一个分区会存在多个分区目录,而ClickHouse定时任务会自动合并分区目录(默认10~15分钟)。
伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。

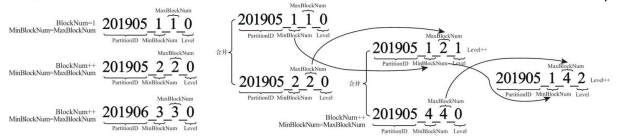
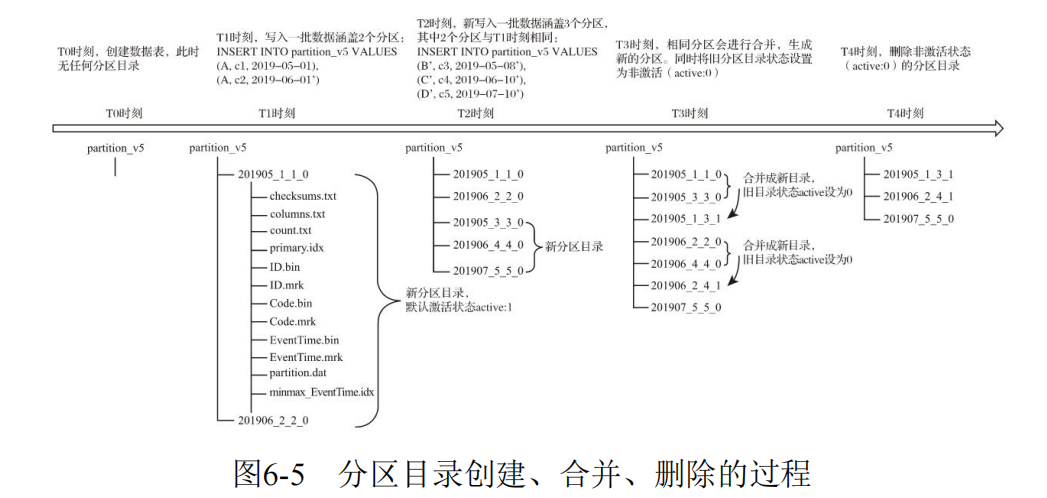
于是我等了20分钟再观察,发现分区真的不断的在减少,每秒减少200个分区。
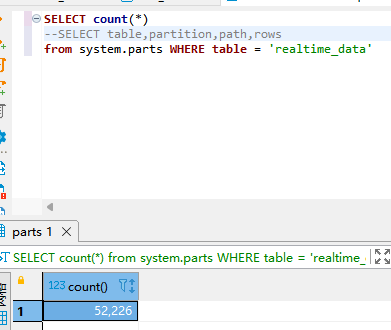
1.3 分区目录合并过慢问题
分区目录合并过慢,导致物联网产生的数据每秒都在insert,而每次insert都会产生新分区目录parts,但由于total_part<10w限制而无法写入至clickhouse。
通过SQL观察,分区目录合并时,每秒才合并不到10个分区目录,而写入速度远远大于合并速度。
SELECT count(*)
--SELECT table,partition,path,rows
from system.parts sp WHERE table = 'realtime_data' and sp.active = 1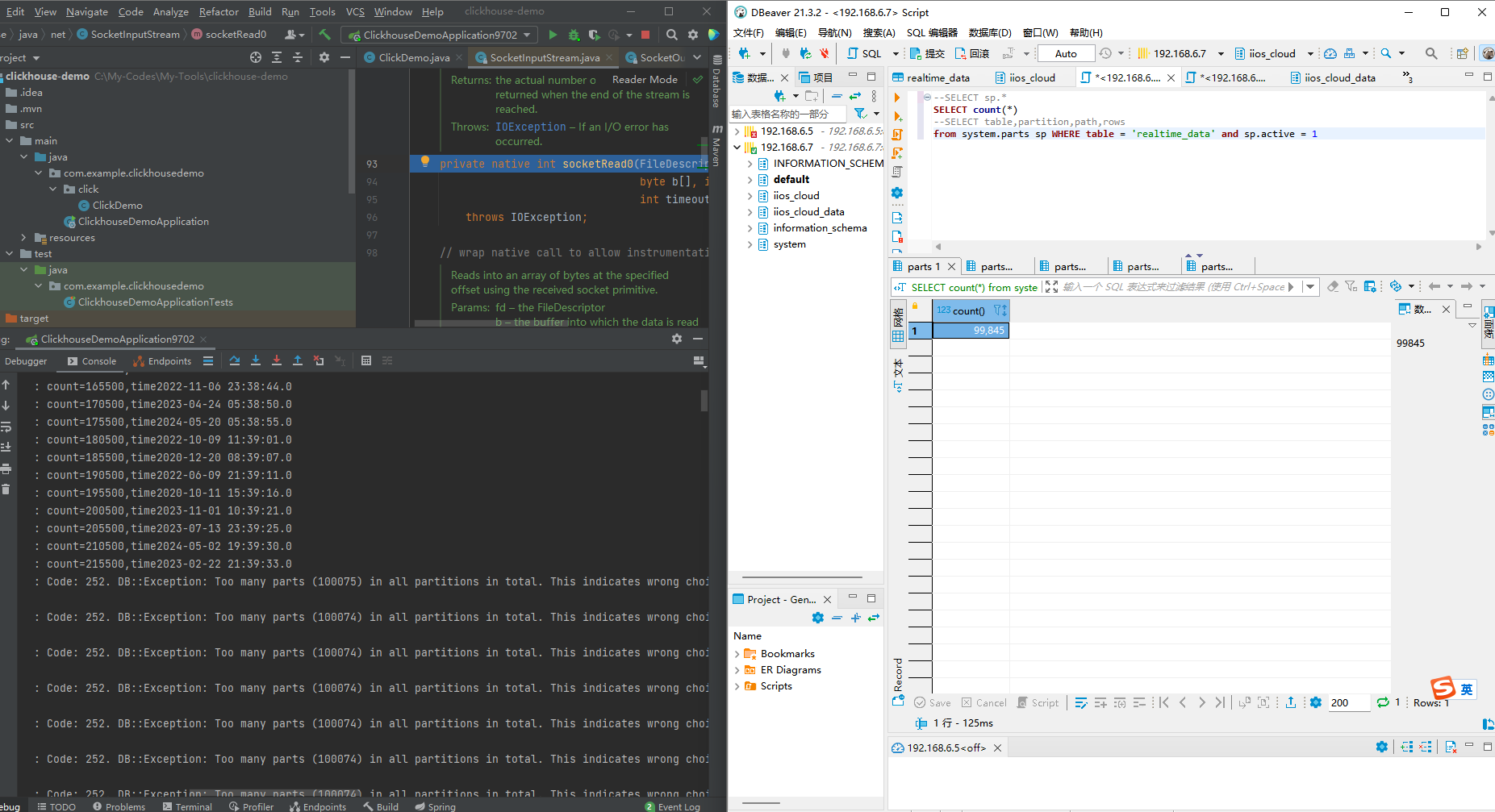
可以观察到合并的速度非常的慢,很多目录一次都未合并过。
解决方法,使用Buffer引擎。
Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储,所以当服务重启之后,表内的数据会被清空。Buffer表引擎不是为了面向查询场景而设计的,它的作用是充当缓冲区的角色。假设有这样一种场景,我们需要将数据写入目标MergeTree表A,由于写入的并发数很高,这可能会致MergeTree表A的合并速度慢于写入速度(因为每一次INSERT都会生成一个新的分区目录)。此时,可以引入Buffer表来缓解这类问题,将Buffer表作为数据写入的缓冲区。数据首先被写入Buffer表,当满足预设条件时,Buffer表会自动将数据刷新到目标表。
