一、介绍
参考《ClickHouse原理解析与应用实战》图书,作者:朱凯。
二、使用入门
2.1目录结构
核心目录
(1)/etc/clickhouse-server:服务端的配置文件目录,包括全局配
置config.xml和用户配置users.xml等。
(2)/var/lib/clickhouse:默认的数据存储目录(通常会修改默认
路径配置,将数据保存到大容量磁盘挂载的路径)。
(3)/var/log/clickhouse-server:默认保存日志的目录(通常会修
改路径配置,将日志保存到大容量磁盘挂载的路径)。
配置文件
(1)/etc/security/limits.d/clickhouse.conf:文件句柄数量的配置,
默认值如下所示。
(2)/etc/cron.d/clickhouse-server:cron定时任务配置,用于恢复
因异常原因中断的ClickHouse服务进程。
2.2客户端访问接口
ClickHouse的底层访问接口支持TCP和HTTP两种协议,其中,
TCP协议拥有更好的性能,其默认端口为9000,主要用于集群间的内
部通信及CLI客户端;而HTTP协议则拥有更好的兼容性,可以通过
REST服务的形式被广泛用于JAVA、Python等编程语言的客户端,其默
认端口为8123。通常而言,并不建议用户直接使用底层接口访问
ClickHouse,更为推荐的方式是通过CLI和JDBC这些封装接口,因为
它们更加简单易用。
CLI
CLI(Command Line Interface)即命令行接口,其底层是基于TCP
接口进行通信的,是通过clickhouse-client脚本运行的。
JDBC
ClickHouse支持标准的JDBC协议,底层基于HTTP接口通信。
JDBC支持高可用模式。
高可用模式允许设置多个host地址,每次会从可用的地址中随机
选择一个进行连接,其URL声明格式如下:
jdbc:clickhouse://<first-host>:<port>,<second-host>:<port>[,…]/<database>在高可用模式下,需要通过BalancedClickhouseDataSource对象获
取连接。
2.3数据分区
数据分区partition目前仅MergeTree表引擎支持。例如使用日期字段分区。
CREATE TABLE partition_v1 ( ID String, URL String, EventTime Date ) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventTime) ORDER BY ID通过system.parts系统表,查询数据表的分区状态:
SELECT table,partition,path from system.parts WHERE table = 'partition_v1' ┌─table─────┬─partition─┬─path─────────────────────────┐ │ partition_v1 │ 201905 │ /chbase/data/default/partition_v1/201905_1_1_0/│ │ partition_v1 │ 201906 │ /chbase/data/default/partition_v1/201906_2_2_0/│ └─────────┴────────┴─────────────────────────────┘使用不合理的分区键也会适得其反,分区键不应该使用粒
度过细的数据字段。例如,按照小时分区,将会带来分区数量的急剧
增长,从而导致性能下降。
三、表引擎
ClickHouse拥有非常庞大的表引擎体
系,截至本书完成时,其共拥有合并树、外部存储、内存、文件、接
口和其他6大类20多种表引擎。
3.1 MergeTree
(MergeTree)表引擎及其家族系列(*MergeTree)最为强大,在生产环境的绝大部分场景中,都会使用此系列的表引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持ALTER相关操作。
合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有所长。例如ReplacingMergeTree表引擎具有删除重复数据的特性,而SummingMergeTree表引擎则会按照排序键自动聚合数据。如果给合并树系列的表引擎加上Replicated前缀,又会得到一组支持数据副本的表引擎,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree、 ReplicatedSummingMergeTree等。合并树表引擎家族如图6-1所示。

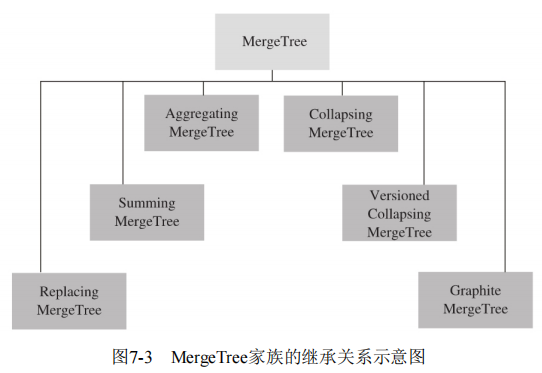
3.1.1 mergetree创建于存储
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
创建语法:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ( name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr], name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略... ) ENGINE = MergeTree() [PARTITION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value, 省略...](1)PARTITION BY [选填]:分区键,用于指定表数据以何种标
准进行分区。分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围,更多关于数据分区的细节会在6.2节介绍。
(2)ORDER BY [必填]:排序键,用于指定在一个数据片段内,
数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序键既可以是单个列字段,例如ORDER BYCounterID,也可以通过元组的形式使用多个列字段,例如ORDER BY(CounterID,EventDate)。当使用多个列字段排序时,以ORDER BY(CounterID,EventDate)为例,在单个数据片段内,数据首先会以CounterID排序,相同CounterID的数据再按EventDate排序。
(3)PRIMARY KEY [选填]:主键,顾名思义,声明后会依照主
键字段生成一级索引,用于加速表查询。默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键,无须
刻意通过PRIMARY KEY声明。所以在一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数(ReplacingMergeTree可以去重)。
(4)SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标
准进行采样。
.......省略,具体参考文档。
3.1.2存储结果
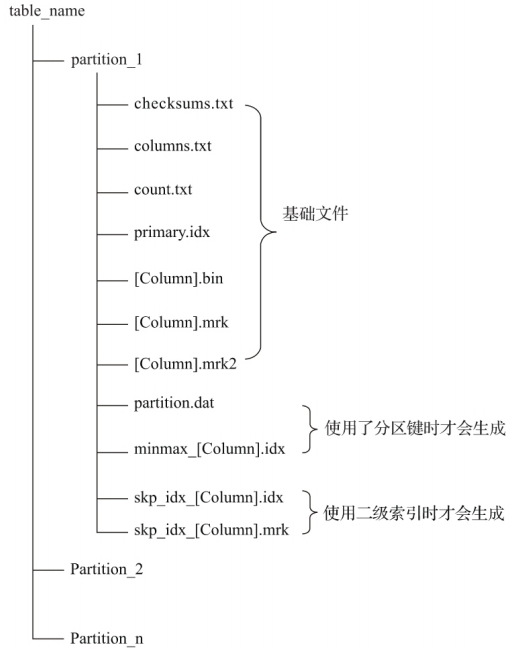
3.1.1 数据分区
通过先前的介绍已经知晓在MergeTree中,数据是以分区目录的形式进行组织的,每个分区独立分开存储。借助这种形式,在对
MergeTree进行数据查询时,可以有效跳过无用的数据文件,只使用最小的分区目录子集。这里有一点需要明确,在ClickHouse中,数据分区(partition)和数据分片(shard)是完全不同的概念。数据分区是针对本地数据而言的,是对数据的一种纵向切分。MergeTree并不能依靠分区的特性,将一张表的数据分布到多个ClickHouse服务节点。
3.1.3 TTL
ttl支持列级ttl,也支持表级ttl。
3.2 Buffer表引擎
Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储,所以当服务重启之后,表内的数据会被清空。Buffer表引擎不是为了面向查询场景而设计的,它的作用是充当缓冲区的角色。假设有这样一种场景,我们需要将数据写入目标MergeTree表A,由于写入的并发数很高,这可能会致MergeTree表A的合并速度慢于写入速度(因为每一次INSERT都会生成一个新的分区目录)。此时,可以引入Buffer表来缓解这类问题,将Buffer表作为数据写入的缓冲区。数据首先被写入Buffer表,当满足预设条件时,Buffer表会自动将数据刷新到目标表。
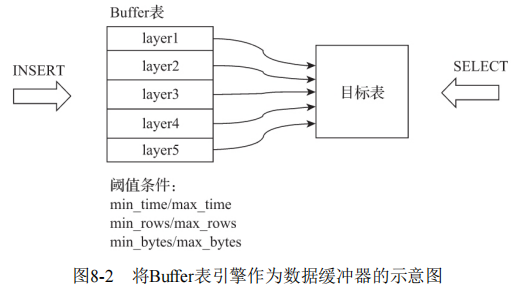
Buffer表引擎的声明方式如下所示:
ENGINE = Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)根据上述条件可知,Buffer表刷新的判断依据有三个,满足其中任意一个,Buffer表就会刷新数据,它们分别是:
·如果三组条件中所有的最小阈值都已满足,则触发刷新动作;
·如果三组条件中至少有一个最大阈值条件满足,则触发刷新动作;
·如果写入的一批数据的数据行大于max_rows,或者数据体量大于max_bytes,则数据直接被写入目标表。
