参考链接:
caffeine:
1. https://zhuanlan.zhihu.com/p/338960997
2. https://www.modb.pro/db/141781
3. https://www.cnblogs.com/rickiyang/p/11074158.html随着宇宙的发展,我方系统受到阿尔法星系影响,吞吐量不足支撑与时俱进的数据要求。
以前的数据分发采用Redis,现在Redis变成了瓶颈之一,遂优化之。
初步思路是设计L1本地Cache,L2网络RedisCache,优先命中L1,以提高QPS。
一、常见缓存介绍
2.1 caffeine
开发入门:https://www.baeldung.com/java-caching-caffeineCaffeine提供了多种灵活的构造方法,从而可以创建多种特性的本地缓存。
- 自动把数据加载到本地缓存中,并且可以配置异步;
- 基于数量剔除策略;
- 基于失效时间剔除策略,这个时间是从最后一次操作算起【访问或者写入】;
- 异步刷新;
- Key会被包装成Weak引用;
- Value会被包装成Weak或者Soft引用,从而能被GC掉,而不至于内存泄漏;
- 数据剔除提醒;
- 写入广播机制;
- 缓存访问可以统计;
内部结构
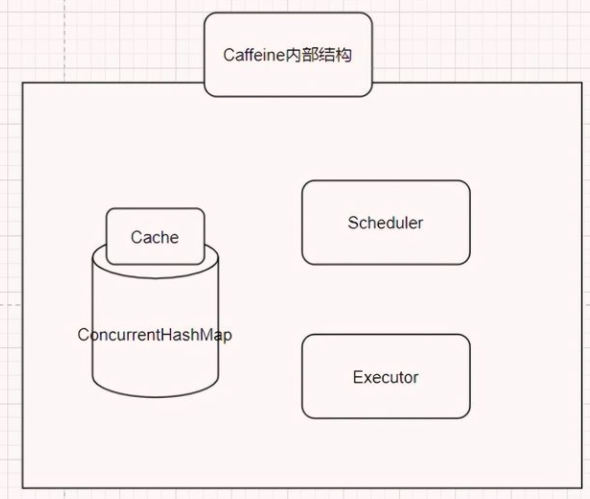
Cache的内部包含着一个ConcurrentHashMap,这也是存放我们所有缓存数据的地方,众所周知,ConcurrentHashMap是一个并发安全的容器,这点很重要,可以说Caffeine其实就是一个被强化过的ConcurrentHashMap。
Scheduler,定期清空数据的一个机制,可以不设置,如果不设置则不会主动的清空过期数据。
Executor,指定运行异步任务时要使用的线程池。可以不设置,如果不设置则会使用默认的线程池,也就是ForkJoinPool.commonPool()
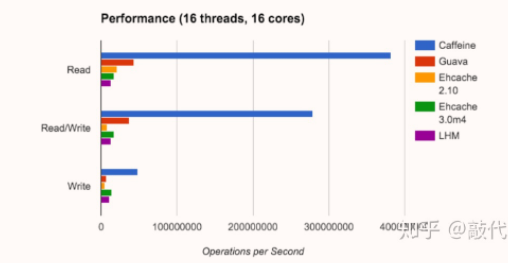
二、性能测试
caffeine官方测评:
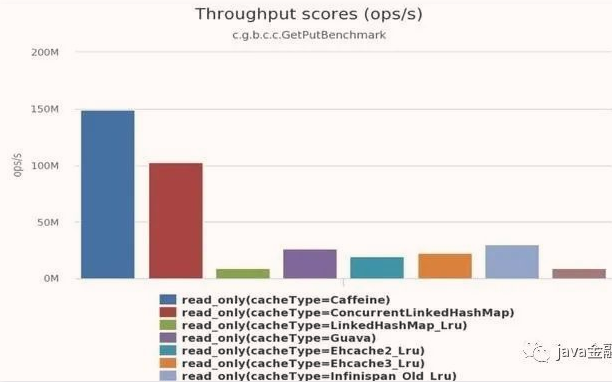
8个线程读,100%的读操作:
6个线程读,2个线程写,也就是75%的读操作,25%的写操作:
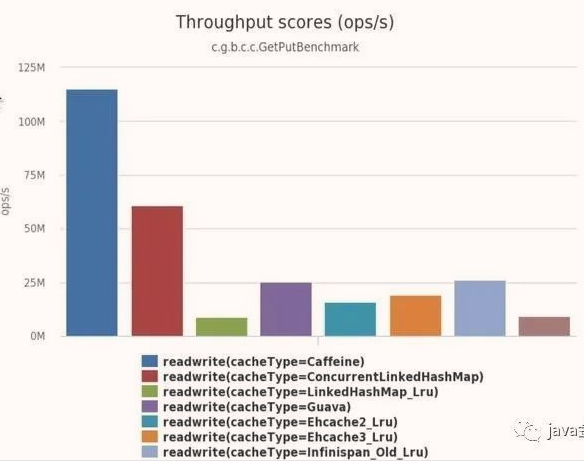
8个线程写,100%的写操作:

