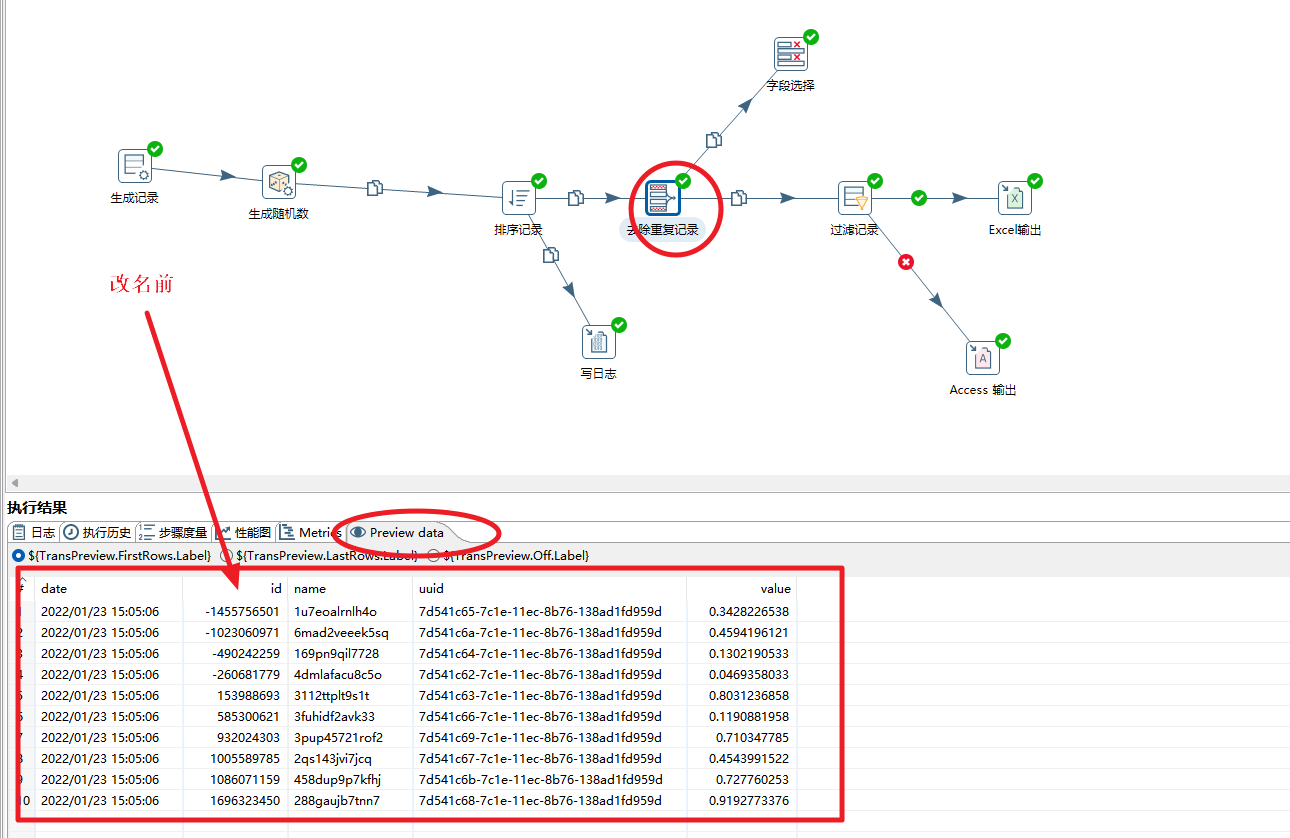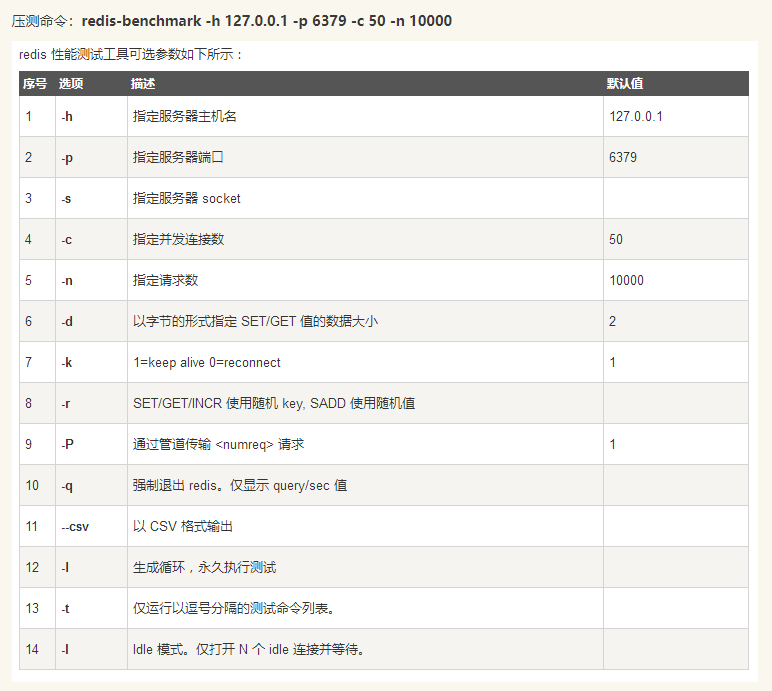
服务的分发效率有点低,测个Redis的基准看看。 测试工具:官方自带的redis-benchmark,windows/linux中都有。 一、使用方法 常用命令: 结果见下:
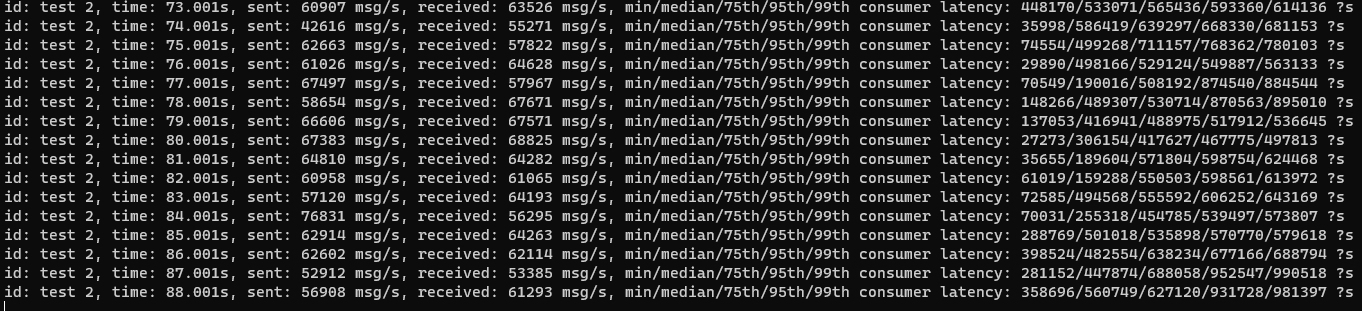
用了几年了,还是四五年前做的性能测试。目前遇到性能瓶颈,为了找出真因,不得不测试下,得到基准线,再根据测试基准线寻求优化。 测试结果: direct 类型 比 topic 吞吐率快2倍左右; 自动ack 比 手动ack 吞吐率快2倍左右; 短期消息持久化对吞吐率无明显影响; rabbitmq使用建议:无额外需求,建议采用direct类型,且自动ACK; 备注:消息量超过2KB后,吞吐较低的原因目前来看,大部分因素的网卡流量问题,4*2KB队列,网卡流量已达到400Mb/S,与峰值几乎一致。其CPU与内存用量未达顶峰…

经常会遇到此问题,每次都要百度,过于麻烦,遂记录。 一、查看正在执行的SQL 应用场景:通过用于查找执行时间巨长的SQL 或 二、查看历史执行的SQL 应用场景:生产环境出现错误,临时看下执行了哪些sql
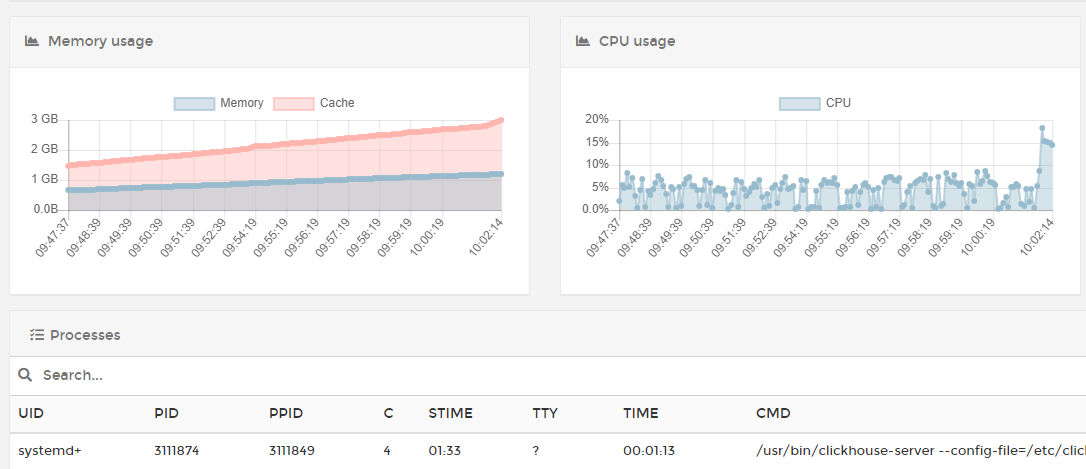
一、问题概览 Clickhouse单表,5W个分区,存储了100亿条数据, clickhouse 重启了45分钟才可以写入数据 。 表结构: 重启期间,内存、CPU资源均不高。 启动成功负载见下: 该问题暂未解决,待博主后续再观察解决。 N、参考资料 链接: https://www.jianshu.com/p/8ef21b2f9244 ;
参考资料: 《ClickHouse原理解析与应用实战》 原始链接: https://ld246.com/article/1517214401442 一、介绍 Buffer,指把数据先写入内存 Buffer 表,再周期性的刷入磁盘表中。读取数据时,会同时从 Buffer 表和磁盘表读取。 Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储,所以当服务重启之后,表内的数据会被清空。Buffer表引擎不是为了面向查询场景而设计的,它的作用是充当缓冲区的角色。假设有这样一种场景,我们需要将数据写入目标Merge…

刚用,拿来存储物联网数据,一个坑一个坑踩。 一、分区方面 1.1 分区数量过多问题 分区策略:终端ID+年月日 数据测试阶段,很快超过十万个分区后,数据无法插入: 解决方法:分区策略:终端ID+年月 1.2 同分区多个分区目录问题 以为max_parts_in_total 已经解决了,但是很快又报错max_parts_in_total错误。 排查后发现,分区出现列表,导致分区数量激增,最多一个分区裂变为28个分区目录,占用了分区数量。具体看下图(1,201911)产生了多个分区目录。 阅读《ClickHouse原理…

一、介绍 参考《ClickHouse原理解析与应用实战》图书,作者:朱凯。 二、使用入门 2.1目录结构 核心目录 (1)/etc/clickhouse-server:服务端的配置文件目录,包括全局配置config.xml和用户配置users.xml等。(2)/var/lib/clickhouse:默认的数据存储目录(通常会修改默认路径配置,将数据保存到大容量磁盘挂载的路径)。(3)/var/log/clickhouse-server:默认保存日志的目录(通常会修改路径配置,将日志保存到大容量磁盘挂载的路径)。 配…